
Notes on exploring the Vasulka PDF archive
14 May 2020Update: Project page is now up, here! Go there if you want demos and a high-level overview of this project.
In anticipation of Recurse Center’s Never Graduate Week (essentially an alumni week time of celebration), a week I had planned to take off from work, I started to think of projects that might fit well into the scope of just one week, both at the angle of R&D work but also technical work. Stumbling through old notes (where my R&D projects hibernate), I came across the Vasulka PDF Archive, an open collection of documents from Steina and Woody Vasulka, video artists and founders of The Kitchen art space.
I think it’s incredible to have acces to a collection like this, just plopped down on the web. I think this collection was arranged and digitized in 2010 or something, and that’s apparent from the web design, which hasn’t been updated since. We’ve come a really long way in the past ten years on the web, and meaningful archival access – something I’m super passionate about, obviously! – can be so much more than just links.
My notes just had a link and said “fix this???”; this note might have even been there since the time I was at Recurse Center two years ago, I dunno.
What are small and reasonable ways that access can be provided to open up this collection, have it make sense at its collection-level rather than random clicking and downloading of PDFs based on their sometimes-descriptive but mostly non-descriptive titles? There is also a folder structure, but it is arranged in a way that it’s difficult to understand. So this is what I set out to explore over Never Graduate Week.
I envisioned this as a series of explorations rather than one final project. This project is already dangerously close to my full-time work. Meaningful archival access is essentially what I already do all day every day. I am in the rare and lucky position of truly enjoying the work that I do, but it doesn’t mean it isn’t work. But so much of work is about maintaining systems over time, being stewards of those systems, and having to push on to catch all the weird edge cases until everything is perfect. So my compromise with this project was that I will be able to explore one aspect of access until I get to the point where I feel satisfied, or it starts to feel like work. And then I will stop. For example, I have no interested in rebuilding a CMS in 5 days.
I don’t know if it will be ready by the time I post this, but I am working on a webpage that contextualizes and links to all of the parts of this project. If this goes first, I’ll update later. STAY TUNED FOR WORKING DEMOS.
So for this blog post, this is going to be more like a series of fragmented notes that I wrote down while working on things, with some light context provided for you, dear reader (and for future me). It’s not cleaned and tidy – maybe I’ll clean and tidy it in the future for something more formal.
So much of what I think about is not just meaningful access of archival material for the end-user (researcher, student, casual internet browser, remixer, etc) but meaningful ways of creating tools that support that access, and given my skillset, a lot of that is spent “demystifying” aspects of technology that have been gate-kept away from others, so I hope the notes can also shed light on this kind of thing.
Step.X - Retrieve all PDFs
If I am working with these things, I have to grab them all.
document.getElementsByTagName('a')
let links = new Array
Array.from(urls).forEach(function(e) { links.push(e.href) })
And here it is (right-click copy object), which I saved as archive-list.txt
I can trim the first three, which are links from the header.
Time to (w)get all these suckers!
wget -w 10 -x -nH --limit-rate=500k -i archive-list.txt
Rate-limiting seemed like the polite thing to do, for my network and for theirs. This took a long, long time. I also initially forgot to include the flags that would retain file directory structure, so everything was ending up in one flat folder. That’s no good, so I had to put those where they belong and kick the job off again. Overall this still took like 16 hours (partially due to a lower limit-rate and because of the stop-restart).
Checked lookup.icann.org for domain registration status: Registry Expiration: 2020-11-27 18:15:46 UTC It looks like it auto-renews, but I’m glad that I will essentially have a copy of this if it unexpectedly goes down.
Used du -h archive | wc -l to check on size,
and find archive -type f | wc -l to check on number.
Total size: 3 GB of PDFs
Total number: 3304
That’s funny, my archive-list.txt is 3305 lines long. I think I deleted a duplicate and then decided de-duping wasn’t worth it.
Step.X - Apply OCR
Can use pdf2text to make a txt file from each pdf?
(Yes)
Used a quick bash script to do this
Step.X - turn txtfiles into json doc
Another bash script, don’t judge me
This sure made some messy data!
[20/05/14|11:24AM] ▶ wc test.json
1 10046522 58960027 test.json
I had to remove the last comma
tac test.json | sed '1,1s/,//g' | tac > new.json
And make ids equal to where pdfs live
sed -i -e "s|../ocr||g" new.json
More messy data! Came into this bug. DIACRITICSSSSSSS.
Step.X - the index
My hacky way of loading data is appending var data = to a json file and adding it in like <script src="data.js" ></script>,
and
despite this being a pretty hefty json file (text editor takes a while to open), it worked quickly.
“Lunr.js should be a possibility.” …is something I wrote before realizing it is absolutely not.
I spent quite a while on this before realizing I am just pushing too much data into something that is not meant to handle so much. I am a monster! Here are my notes before I got to that point because I am stubborn:
Will have to create a document array and loop through and add all txt files as a structure, with whatever will be used as ID (filepath probably), and can pre-build the index but should be ok.
Need to make sure to include Lunr.js support for other languages: I’ve seen French, and a Scandinavian language.
Lunr.js is fast but breaks when things are too big.
sql.js as another possibility. sql.js is slow but … well … maybe it doesn’t have to be, but I probably shouldn’t be using JavaScript.
Okay, I know, I work with a lot of super as-light-as-possible light things. I don’t even like to use npm for anything. I like pure, simple, static things with pure HTML, CSS, and JavaScript and no external libraries. This is a combination of me be lazy (90%) and wanting things to just work quickly (10%). And considering most of my projects are small divniation applications, that isn’t much of a problem.
But now I think I am going to have to again pull out the big guns.
But wait?
To configure your current shell run source $HOME/.cargo/env
tinysearch seems perfect! using Rust+WASM but still the benefits of being in the browser.
It wasn’t. I saw an old familiar friend:
Error: NotEnoughSpace
OK OK OK OK OK OK! Big guns time.
ElasticSearch is out. I have to encounter it at work and it brings me no joy. (This is where a Marie Kondo emoji would go.)
Postgres is interesting. It was a joy when I worked with it, and it was nice to me. Urgh, not really wanting to do a whole thing though.
WAIT, sqlite?
sqlite won! It’s not going to win any speed tests, but it was fast (to put together) and cheap (could use free hosting).
I used glitch, because I could load in my sqlite database and render it easily. Loading it in is kind of hacky, you have to add the sqlite db to the assets folder as if its an image, then go into their Terminal and copy it over to a usable path, and then load it up. It is in line with the hack-this-fast punk ethos of this project, I think.
Free text search was a big thing for me, and it’s slow but I have it. This could obviously be scaled up with a better database, which would vastly improve the speed. But the absolute last thing I am going to do on my VACATION is something like that.
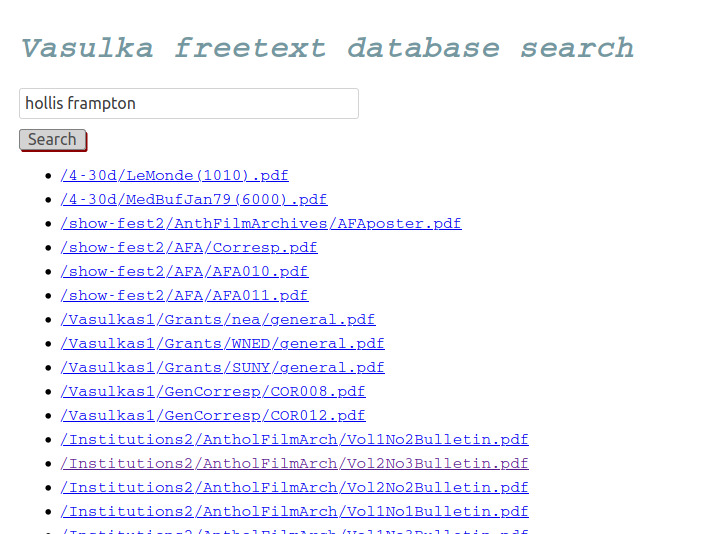
There’s definitely more to do here than the absolute proof-of-concept it’s at right now, which is returning filenames and links to the hosted files when you do a free text search. I’ll come back to this, time-allowing. Onto the next!
Step.X - Apply thumbnails
Can use convert to make thumbs from all images, then can display them. Need to grab either first image, or all images.
The chorus of this blog post: Used a quick bash script
I grabbed first image, so every PDF has one associated thumbnail, instead of some having many.
Step.X - Making search usable
I wasn’t ready to tackle image arrangement, so I went back to the search to make it actually functional. I left it being like “oh good, this is possible” but I was hardcoding variables everywhere.
I guess I don’t have interesting things to say about this section; I’ll just say it took me way longer than anticipated for nothing but stupid syntax reasons.
Step.X - Make a montage
Let’s start by making a montage of all of the thumbnails, which can be used a spritedeck, depending on how huge it is.
find thumbsarchive -type f -name '*.jpg' > path-to-thumbs.txt
montage -label %f -frame 5 -geometry +4+4 @path-to-thumbs.txt montage.jpg
Oh, it’s 24MB! Maybe not.
I took out the extra bells and whistles and it became 15MB.
Maybe I can get it down even more, but I don’t see an easy way to make the css for a spritedeck and it’d be a massive pain to handle all of these, too much.
Step.X - Make a wordcloud
I started really wanting some QUICK WINS as Friday started to loom, so I used word_count to make one and the results were hilarious.

Whoops, I converted the wrong file!
Okay, after collecting all the OCR files into one:

Got something more normal. It is a bit like an aggressive poem. It got better from there:

and so on, and so on. It got better. But I didn’t come all this way just to make wordclouds!
Step.X - Arrange by likeness
Something I really wanted to do was arrange images by their likeness, and cluster them.
It’d be nice to take the time to build exactly what I need, but I don’t have a lot of time in the scope of this project to really put something together like that, so I went on the hunt for a library that did what I was looking for. It led me down some good paths to explore in the future, and different algorithms to investigate.
After a while, I found a library that seemed like it would do the trick in a pinch (which I am increasingly in): https://github.com/victorqribeiro/groupImg. The demo video looks perfect!
So I needed to flatten my images down to one folder but retain their filepaths: find archive -type f -exec sh -c 'new=$(echo "{}" | tr "/" "-" | tr " " "_"); mv "{}" "$new"' \;
This was nice, I was able to organize all of the files into categories of likeness. I can see that being extended out to be a useful means of access, exploring similar images. I made 10 categories.

This one was the best group and the smallest. This gave me a pretty good understanding of the collection at a larger level insomuch that there are a lot of very similar black text on white paper scanned documents, and some full scans of old magazines. But mostly I felt like this was a way to seek out “interestingness”. With just relying on image thumbnails of the first page, though, how much more can I get?
Oh, as you can see above, this also did a great job of pointing out duplicates, because they sat right next to each other. I did notice a duplicate Vogue cover that was in two different montages because one was black-and-white and one was in color.
Step.X - Folder significance - thinking big
The collection is organized into different folders, and their significance isn’t clear when everything is just a near-flat list. Something like this would be a nice layout for understanding where files exist within a structure, particularly the part of the collection that involves grouping by artist names that would be valuable for researchers seeking out that particular artist. This example is pretty much an out-of-the-box D3 visualization, and I think a lot could be done to make it more visually appealing and useful. It’d be nice to represent size of the contents of each folder too. I am thinking of it like bubbles that burst into smaller scaled bubbles, up until getting to the files which can be represented as a flat list. I have no idea what the guy is talking about, but this visualization is what I have in mind.
I am describing this because I don’t think I have time to build it by the time I end this exploration week.
Maybe I can spin something up based on this blog/tutorial also covered in this video.
Step.X - Folder significance - thinking fast
Okay, after browsing around what the open source community happens to offer (for quick-quick!), I found this great and well-documented library with lots of example demos, Treant.js.
The problem is that there are 693 folders, oof!
But I managed to get it working, the problem was still that it is far too wide to resonably display out-of-the-box this way.
Even shifting this around, it’s a bit too big to work with.
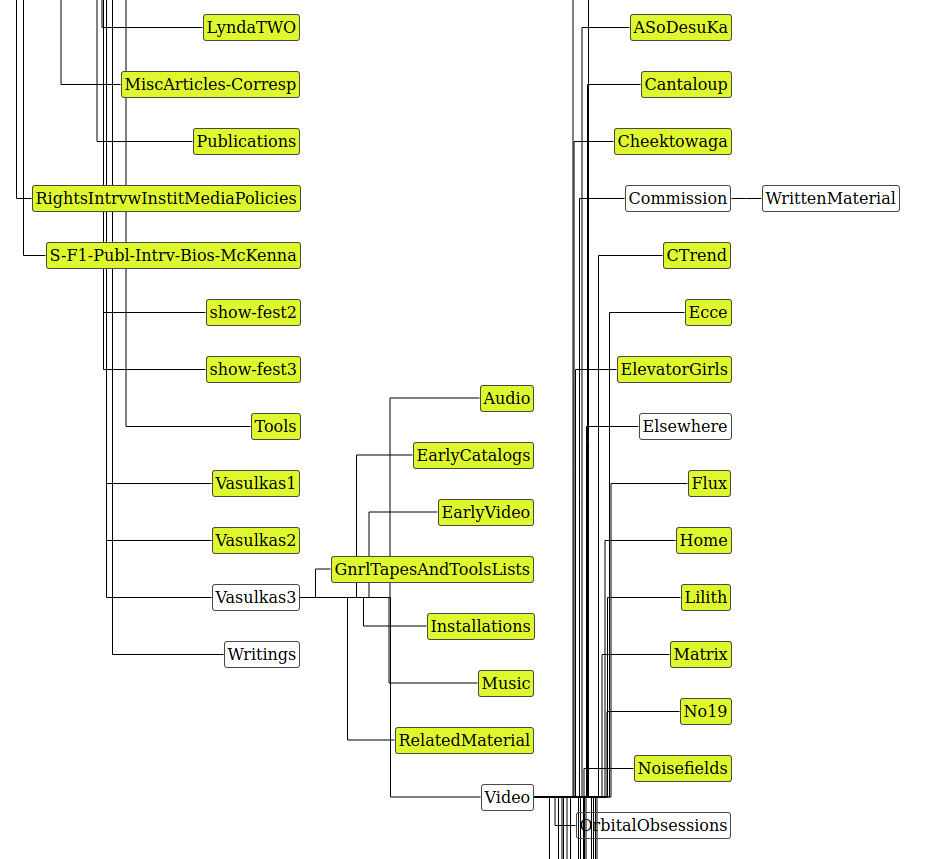
I’d like to instead focus on the bubbly idea, like above, as a way of letting people know which folders have a lot more content inside of them, which ones don’t have more, and have it all appear on the screen instead of having to spend so much time scrolling. This overall is a tiny bit better than what is already there, but not by much (and mostly the benefit comes from the spacing). This doesn’t represent which folders have more folders in them at a glance.
Step.X - Drag them
I think at every point in an archivist’s career, she gets fed up and wants to just throw papers everywhere, and people working in digital archives probably have that urge even stronger. So of course I’m working on something like that.
Step.X - Human elements
All of this work to get as far as I can in understanding the data using only computers really speaks to the significance of archival practice. For example, there’s a folder called NamJP, and it’d take quite a leap for a computer to be able to connect that to Nam June Paik, but it’s something obvious to a person with a bit of domain knowledge. Even throwing machine learning onto this, I don’t know if it can make those connections yet, given the limited extent of the collection. Computers don’t know about the history of video art… yet.
Conclusion
There’s lots more to do, but I have to get back to everything else I have going on! I do want to shape this up into a webpage that goes into these explorations (and maybe as a way to teach how?) in a tidier way.
I think this would be amazing to teach as a class over 16 weeks – “Building a Collection Management System from scratch.” Any takers??
Thank you to my partner Rory for patiently listening to me ramble and rant on niche topics, muddle through potential ideas and foolish paths, and for probably being the only person who made it to the end of this blog post. 😇