
Media Collection Viewer
03 Apr 2021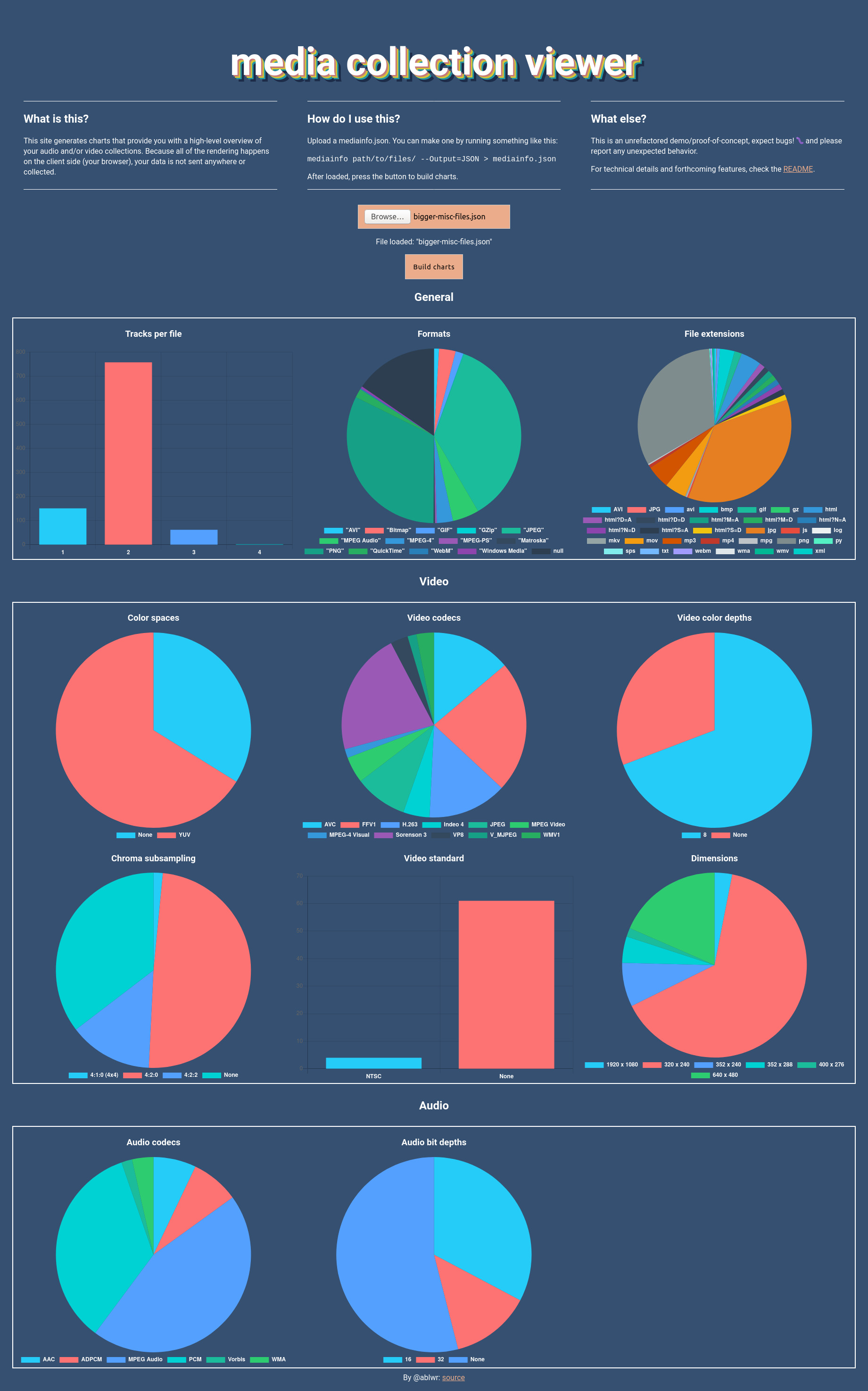
Overview / project vision
I’ve spent the last few weekends working on this thing, tentatively titled Media Collection Viewer (and it seems like that name might just stick!). The way it works is that you provide it with a valid JSON file derived from the audiovisual file analysis tool MediaInfo and it produces charts based on that data, so that you can get a broad understanding of the files you are having to handle.
(Note: Through some testing, I found out that older versions of MediaInfo won’t give you valid JSON – there’s a gap between the experimental feature and when it became functional. oops! I think version 18.08-1 is when this was addressed; I mostly tested with v20.03.)
I think this fills a few needs in the archives field and beyond, which are:
- Discovering/receiving a hard drive full of videos, but you don’t know much about them, or even about video in general. I encouter this pretty frequently at my job, and it helps to know what the overall specification of the files are (beyond their file extensions, which can be misleading and not tell the whole story) in order to provide recommendations for preservation management.
- Receiving files back from a digitization vendor and you want to do some QA to make sure everything is aligned with the specifications you requested (i.e. there’s no outliers from the requested colorspace, dimensions, tracks) Also at my job, I feel like I’ve seen it all! There can be a lot of surprises/errors.
- General checking for “gotchas” like an unexpected amount of audio tracks or timecode data that need to be handled in a different way. In order to think about how to deal with them, you first need to know about them existing.
- Obviously… presenting data about collections to your boss or at a conference! Charts are way cuter than raw JSON data or yet another picture of a spreadsheet on a screen.
My project goals (also outlined in the README) were:
Fast
I’ve worked on these kinds of projects often, and processing speed is always an issue. I wanted things to move fast, so people aren’t waiting around for their charts to render. I succeeded here, and as noted by an early tester, the charts are way quicker than getting the MediaInfo output in the first place.
Sturdy
I didn’t want something that needed a lot of assistance for someone to use. Sometimes digital archivists can’t or don’t know how to use the command line and get the data they need, so they may need to ask someone for help with that, but I didn’t want subsequent issues around this tool. I’ve reasonably achieved this, although there is still a gap in talking people through what the expected input is and possibly better error-handling.
Client-side only
I wanted this to be safe for people to use without having to jump through hoops and talk to lawyers – lots of video data is either private or has not yet gone through the rights management bureaucracy to be deemed okay to share. I achieved this by making it client-side only, so that data doesn’t leave the browser.
Deployable for free
I don’t want to pay to stand something up. This lives on Microsoft GitHub for free, which I’ve used for many years as a free hosting platform (including this blog). Some could argue I’m doing some soul-selling here, but I don’t have any additional billings.
Easy to use
Similar to being sturdy, I want this to be easy for someone to use, assuming they have the right data to work with. It should be straightforward and not require much thinking.
Technical things
To achieve these things, I went with using Rust, WebAssembly, and JavaScript. Rust for the speed and sturdiness, WebAssembly for the client-side, static-site rendering, and JavaScript for making charts that look cute.
I fought the compiler often, which is typical with Rust, but I was able to get things going relatively easily. Still, I struggled endlessly with types and borrows and all the usual things that frustrate new Rust users. It felt frustrating in a reasonable and expected way. I was able to get a proof of concept up and running, and looking exactly like it does now except with less charts, in about a day’s worth of work. If I did programming at my day job (unfortunately I do basically zero these days 😭) and I had spent any time with Rust in the last three years, I’m confident that it would have gotten itself together a lot sooner.
I wanted to produce an actionable proof-of-concept and then focus on refactoring later, which is what I did. Things were pretty hacky, but I figured I’d sort them out later (no premature optimizations here!). I then spent a week living in a weird depressive despair after trying to “fix” the code to make it super optimized and elegant and all the things you want to do, but failing to do so. So, it remains. After more than half a bottle of prosecco and pair programming with someone who does do this every day, and explaining all the things I had tried and why they can’t or don’t seem to work, I was finally able to come to terms with the code quality. Usually I don’t really give a shit about this kind of stuff, but maybe I was channeling pandemic horror and unhappiness and all of my self-worth into my inability to refactor my code into a perfect vision of what shippable software looks like, even though all of my requirements outlined above were achieved (and it’s still plenty fast).
I think the pandemic has made my ego especially fragile and my brain/body constantly exhausted, on top of already being on the brink, and I think that’s true for a whole lot of people but I still manage to see it as a personal failing. I sort of roll through every possible negative thing that anyone could say to me about this project instead of appreciating the positives: that I set out to do something and was able to do it in a short amount of time, it is something that I think can provide a lot of value to a lot of people, and I’m not getting paid to do any of this work so I shouldn’t get so upset about this thing I’ve managed to put together in my free time in a year where everything has been a crumbling disaster all around me.
Well, uhhhhhhhhhhhhhhh that’s it! I hope you give this little thing a try and I hope it helps you out! I have a handful of more things that I want to add, and a few big things too that I might never do, but I am happy with how it so quickly turned into a functioning little application (after getting over the aforementioned naval-gazing spiral) that I can recommend to people trying to get a better understanding of their video collections without too much work.